Prédiction de volatilités¶
Présentation du jeu de données¶
Introduction¶
Dans le cadre de la gestion de capital, le risque associé a un port-folio d’actif est une quantité primordiale dans l’équilibrage de ce dernier. Dans le cadre de stratégies plus aggressives, la volatilité de fin séance est une variable d’une grande importance pour des raisons de gestion du risque et d’optimisation des résultats. Capital Fund Management (CFM) a ainsi en 2018 proposé comme défi d’apprentissage automatique l’estimation de volatilité de cloture sur les marchés actions US. Il existe de nombreuses manières de calculer la volatilité d’un actif et CFM a imposé sa propre formule non divulguée, la volatilité dépendant de la modélisation que l’on considère la mieux adaptée pour un actif et une stratégie donnés.
Le jeu de données est composé, pour un ensemble d’actions (318 précisement) issues du marche américain de la volatilité et du signe du rendement (au sens de CFM) toutes les 5 minutes de 9h30 à 14h pour un jour donnée. A partir de ces données historiques de volatilités devait être prédit la volatilité moyenne des deux dernières heures avant clôture de la journée. Ainsi on dispose de séries temporelles pour un ensemble de date et de produits fixés (ces classes sont approximativement équi-distribuées), chacune de ces séries étant associée à une grandeur réelle positive à prédire.
Nous disposons, de plus, d’un second jeu de données test, où les cibles sont absentes, et dont la précision des prédictions est obtenue en soumettant nos résultats à CFM.
De manière surprenante, le choix de la métrique est la MAPE, qui est connue pour son instabilité et qui est malheureusement peu supportée par les bibliothèques standards de Machine Learning.
De l’aveu de l’organisateur lui-même, faire sensiblement mieux qu’une régression linéaire aurait très difficile. Ce constat est partagé à la suite de notre étude. Étant un challenge déjà terminé, le meilleures score est public et s´élève à 20.7%, obtenu semble-t-il par stacking de réseaux de neuronnes.
Ce challenge nous a permis d’améliorer notre méthodologie, mesurer la difficulté d’optimiser un modèle qui marche déjà bien, nous a réservé des surprises en termes de compromis biais-variance (rajouter des colonnes peut sensiblement détériorer un modèle) et nous a permis de s’essayer à des bibliothèques de Machine Learning montantes.
En raison de la taille de nos données, et comme nous le verrons plus loin du nombre de modèles à générer et optimiser, nous avons choisi de réaliser notre projet en python. Nous utilisons ainsi la bibliothèque H2o, qui couplée au cluster de calcul de l’université Paris-Sud, permet d’optimiser nos calculs et de les paralléliser
Description succinte des données¶
Les données contiennent trois groupes de variables prédictrices:
volatilités: 54 colonnes qui represente les volatilités prises toutes les 5 minutes de 9h30 inclus à 14h exclus.
signe du rendement: 54 colonnes avec le même échantillonage que précedemment.
contexte: 3 colonnes identifiant du produit, identifiant de la date, identifiant unique de la série temporelle.
Les identifiants associés aux dates ont été mis au hasard sans considérer leur caractère séquentiel. Les identifiants des produits sont anonymisés.
Le nombre de date de quotation s’élève à 2117 jours, sachant qu’il y a 253 jours de quotation par an, on obtient un peu plus de 8 années de quotation.
Le fait que l’on ne puisse pas considérer les dates de manière séquentielle est handicapant. On ne peut ansi rajouter en terme de colonnes les volatilités du jour qui précéde ou une moyenne des volatilités sur la semaine. Il s’agit cependant d’un choix logique, étant donné qu’il serait possible d’utiliser la volatilité d’ouverture de séance pour aider à la prédiction de la volatilité de fin de séance de la veille, ce qui réduirait considérablement l’intérêt réel des prédictions.
Visualisation¶
Exemple d’une série temporelle obtenue¶
Nous en affichons ici trois et nous remarquons des comportements très différents en termes de pics de volatilités. Ainsi la première série a un pic en début de séance, tandis cela n’apparait qu’en fin d’après-midi pour la seconde, tandis que les pics de la troisième ont lieu en début et milieu de matinée.
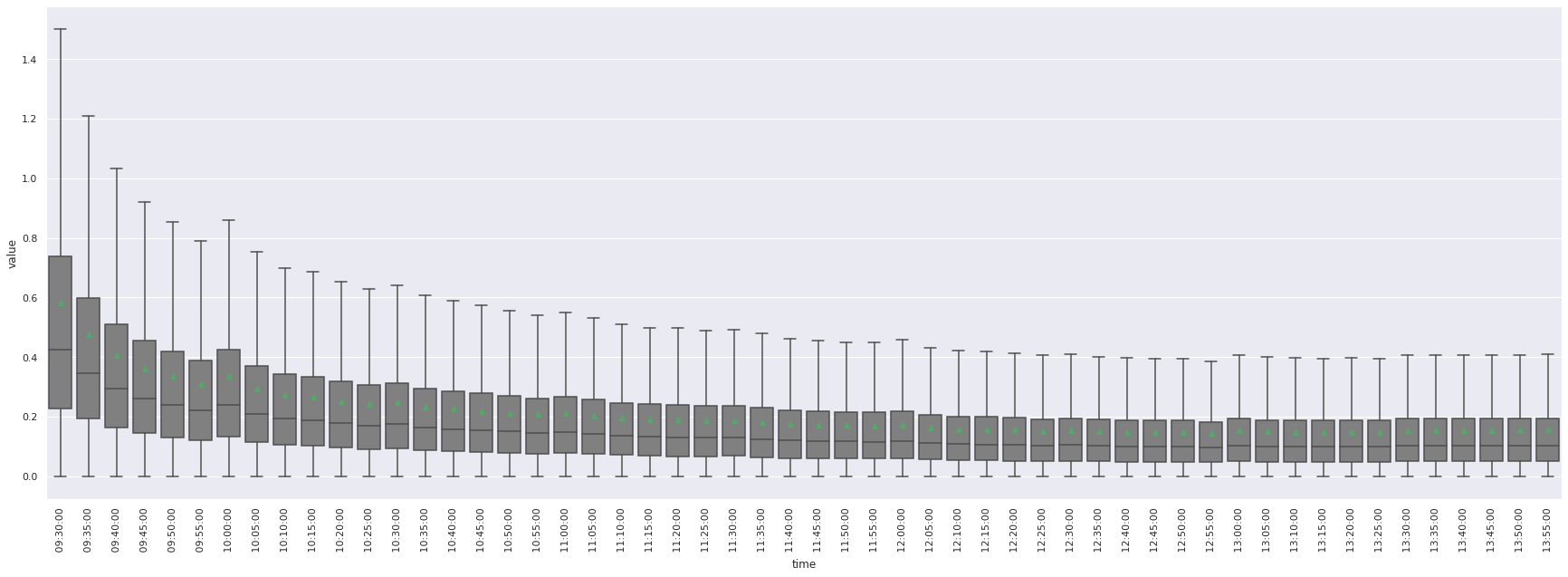
De manière générale, les observations empiriques des marchés financiers décrites dans plusieurs articles permettent de constater une forme de “U” au cours de la journée, avec une volatilité forte en début de session, plus faible en milieu de journée, avec une remonté en fin de session, sans toutefois généralement atteindre la volatilité de début de session.
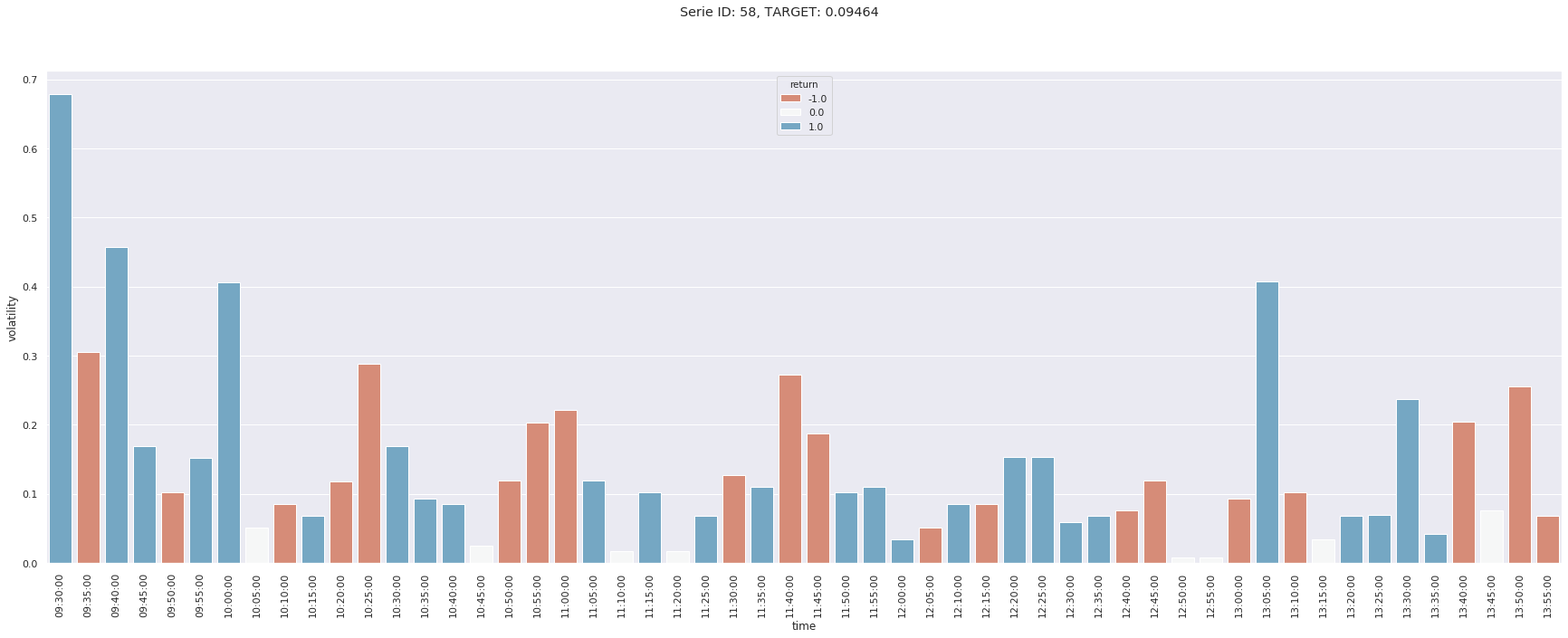
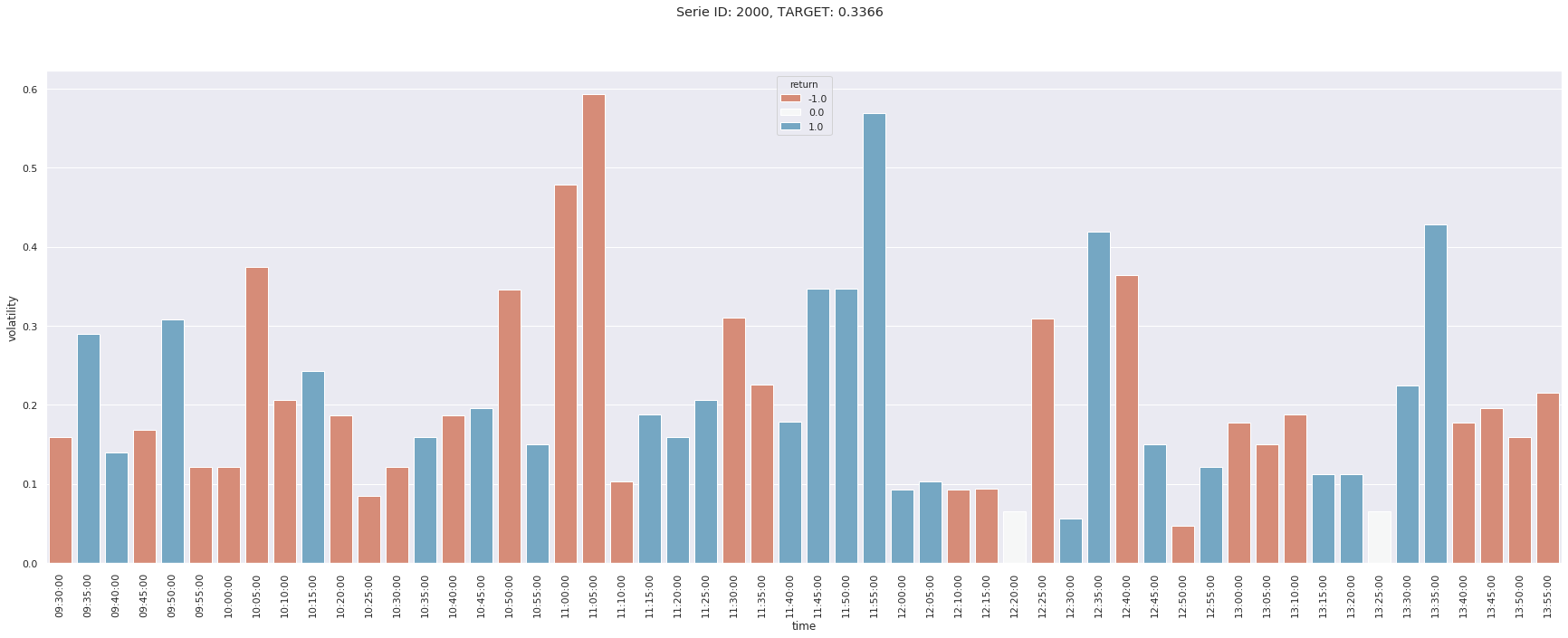
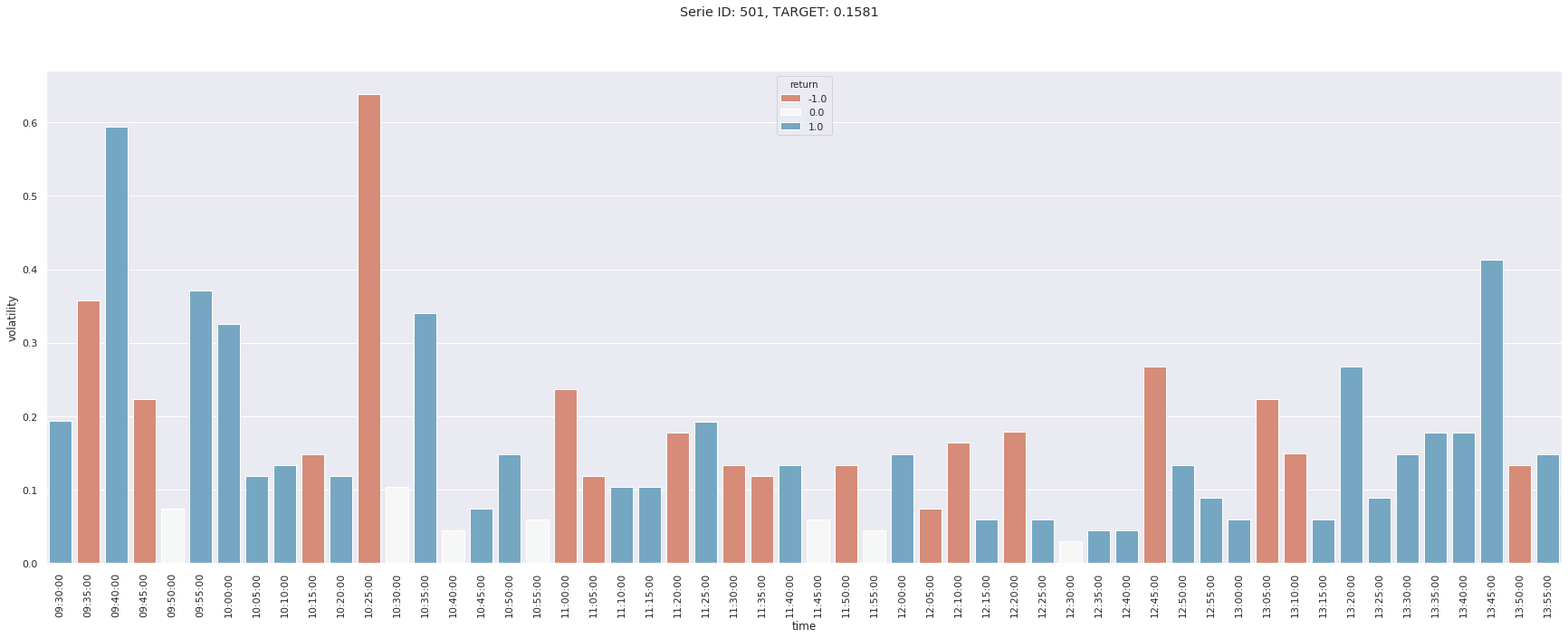
En étudiant la distribution des volatilités conditionnellement à l’heure de la journée, on remarque ainsi, comme espéré, une très forte volatilité moyenne en début de séance.
L’affichage des outliers a été désactivé dans ce boxplot par soucis de visibilité. Les points triangulaires verts repésentent la moyenne de volatilité pour l’horaire considéré.
Distribution des volatilités¶
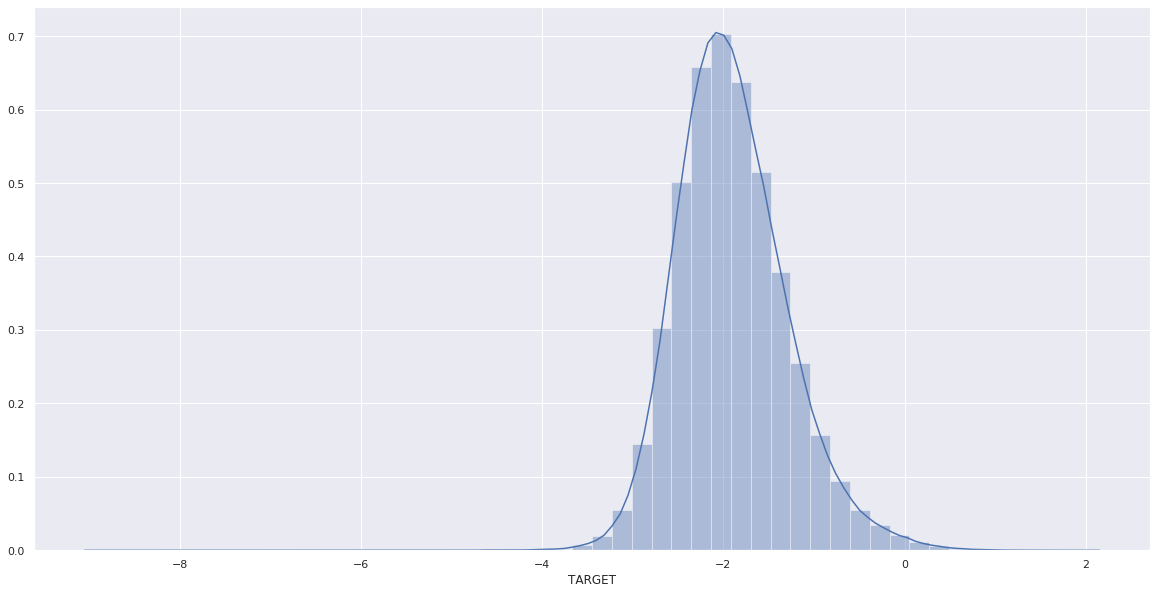
Nous constatons visuellement que la log-volatilité sur les deux dernières heures avant fermeture suit presque une lois de student. Cela est en adéquation avec les observations empiriques du marché financier, où la log-volatilité bien que proche de la loi gaussienne affiche cependant un phénomène de fat-tail.
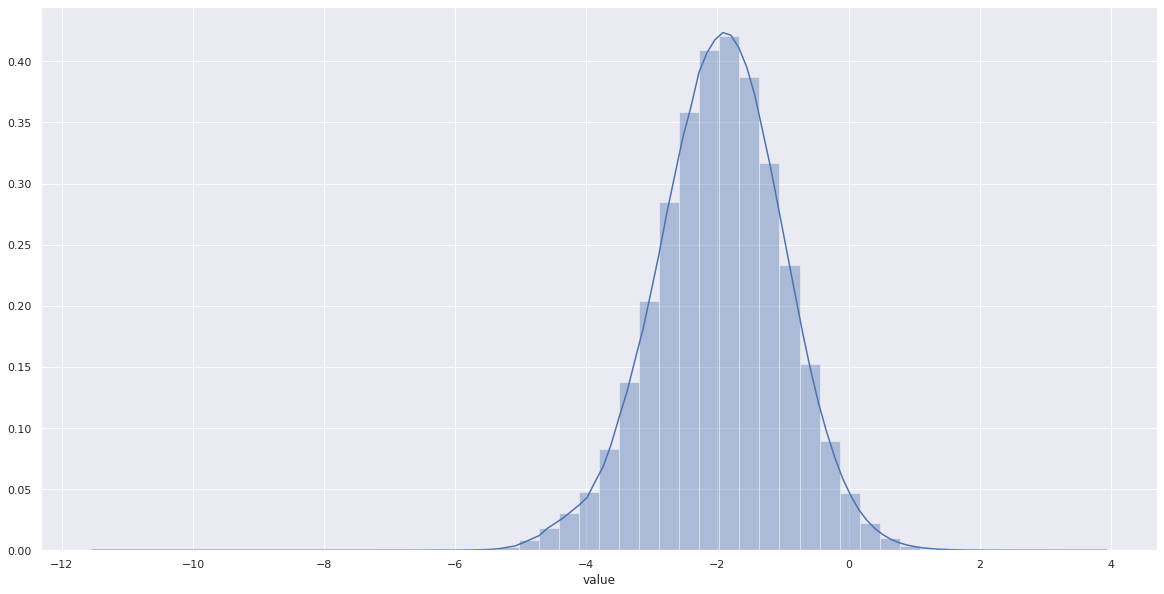
De même, si on regarde les log-volatilités du matin, on obtient des distributions identiques en enlevant les sur-représentations en 0.
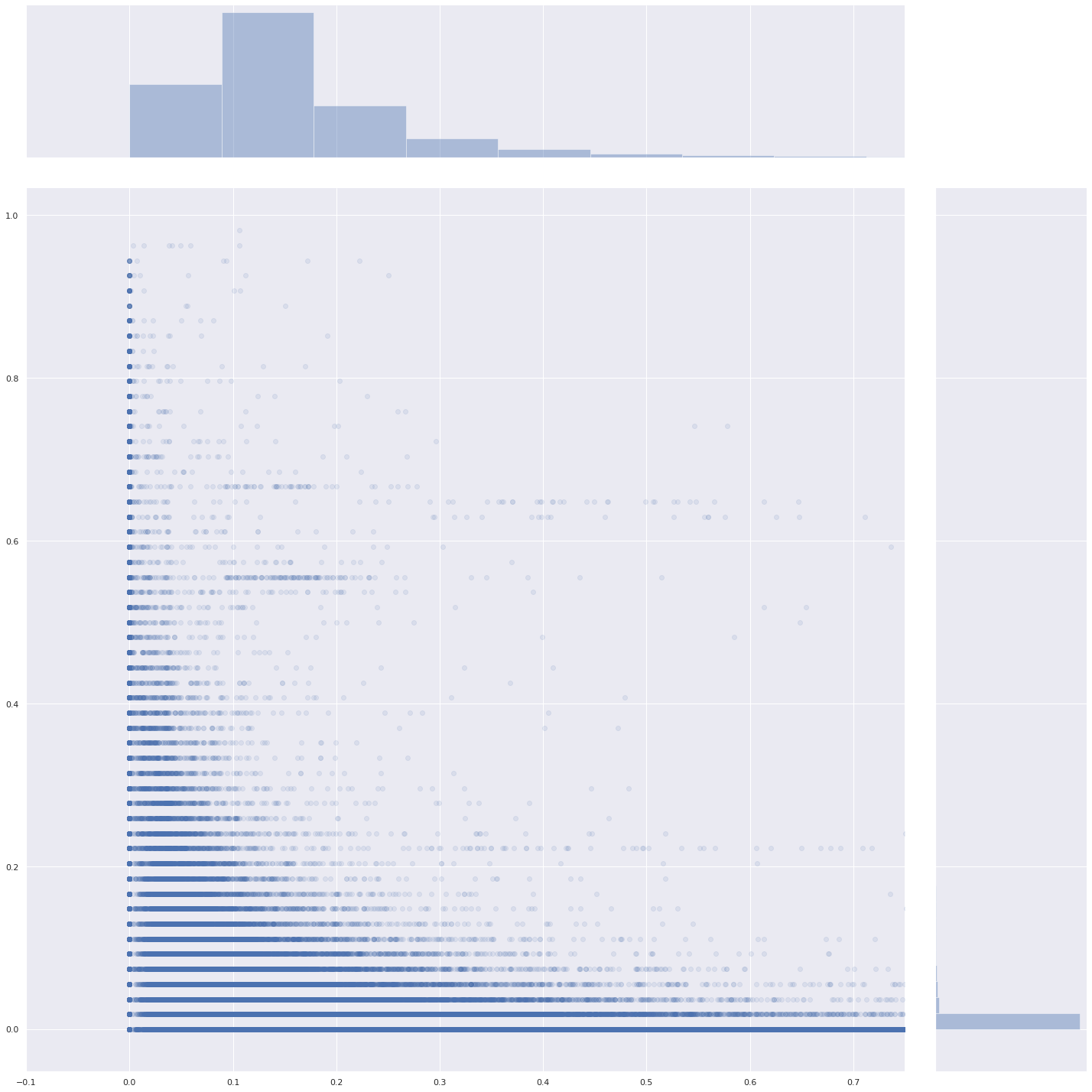
Nous pouvons constater que la volatilité est nulle pour 4% des features :
value |
|
|---|---|
sum |
1.565805e+06 |
mean |
4.556938e-02 |
Notons aussi la proportion de valeurs manquantes :
value |
|
|---|---|
sum |
419817.000000 |
mean |
0.012218 |
Malheureusement, il est particulièrement difficile d’utiliser cet observation afin d’améliorer un modèle minimisant la MAPE.
Données Manquantes¶
Un des problèmes majeurs relatif aux données est la présence de nombreuses valeurs manquantes, aussi bien au niveau des features de chaque actif, que de la répartion des produits par date. L’absence de features s’explique pour deux raisons principales :
Instabilité du cours qui oblige la suspension de la quotation, mais cela reste particulièrement rare.
Aucun mouvement du cours, ce qui fait qu’il n’y a pas de mise a jour du prix du titre, ce qui indiquerait la présence de produits illiquides.
Pour l’imputation de ces données, nous avons adopté une interpolation linéaire pour les volatilités. Concernant les retours manquants, considérant la difficulté de les prédire de part l’aspect tout à fait aléatoire des retours des prix de marchés décrit dans la littérature, nous choisissons de fixer leur valeur à 0.
Un autre phénomène remarquable est présent au sein des données: pour certaines dates, certains produits sont manquants.
La encore, nous pouvons le justifier par:
action non encore quotée à la date donnée, ou retirée des marchés électroniques.
produit totalement illiquide à une date donnée.
volatilité nulle sur les deux heures qui impliquerait une inconsistence avec la métrique
Lien entre date et produit manquants¶
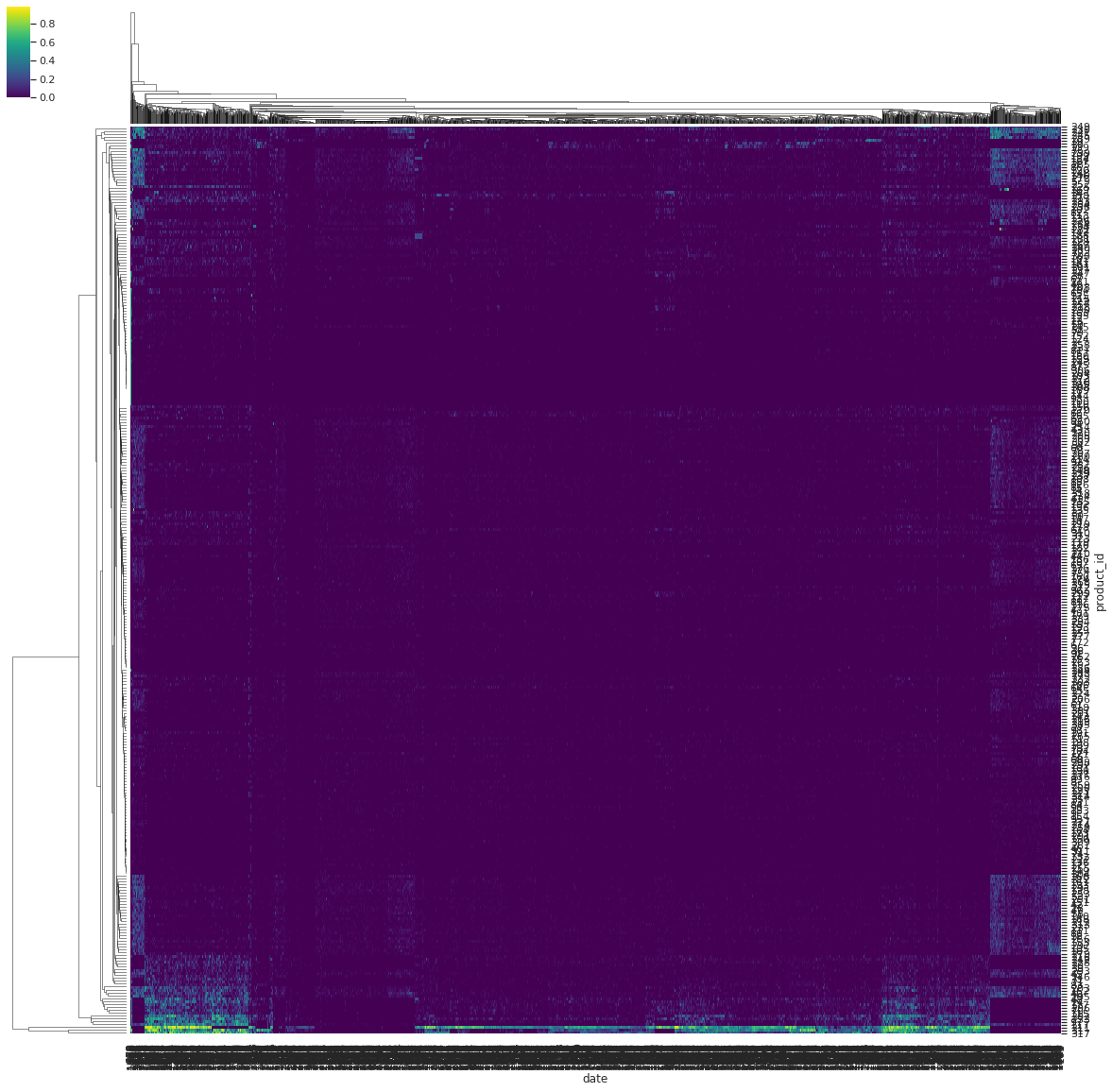
Afin de confirmer l’hypothese d’une très forte corrélation entre un ensemble de date et un ensemble de produits, nous calculons une matrice de presence entre produit et date et clusterisons cette matrice.
On remarque ci-bas en effet que sur l’ensemble d’entrainement les produits manquants sont concentrés sur un ensemble de date particulières.

Volatilités manquantes¶
Le graphe suivant a pour vocation de confirmer qu’en majorité les produits avec des proportions de valeurs manquantes élevés pour un jour donné sont ceux qui sont très peu liquide ce même jour.
Nous clusterisons la matrice qui à chaque produit et date associe la proportion de predicteurs manquants.
Modèles Baselines¶
Dans toute la suite, nous considérons 80% de nos données d’entrainement comme ensemble de train, et 20% de nos données d’entrainement comme ensemble de validation. Ce partionnement est fixe pour tous les modèles, de par l’utilisation de la même seed pour réaliser le partionnement.
Nous présentons ici trois modèles baselines :
Mediane des Volatilités du Matin¶
Le premier modèle que l’on propose n’est autre que la médiane des volatilités du matin, qui obtient le score suivant après soumission à CFM :
26.4254
Régression Élastic-Net basique¶
Comme premier modèle, nous choisissons d’effectuer une simple régression elastic-net sur toutes les features, et sans transformation des features si ce n’est d’interpoler les volatilités manquantes. Nous considèrons 80% de nos données comme jeu d’entrainement, et 20% d’entre elles comme jeu de validation.
Après différents essais, et cela sera d’ailleurs le cas dans tous les modèles suivants, nous constatons que les retours ont un pouvoir prédictif nuls. Nous considérons alors comme features uniquement la moyenne de ces retours sur la journée, ainsi que les volatilités.
Afin d’essayer de se rapprocher de la MAPE, nous pondérons nos pertes quadratiques par \((TARGET)^{(-3/2)}\). Nous effectuons par ailleurs une recherche de la pénalisation optimale sur le jeu de validation.
Nous obtenons les MAPE suivantes sur le jeu de train et sur le jeu de validation.
MAPE |
|
|---|---|
train |
25.193831 |
validation |
26.238252 |
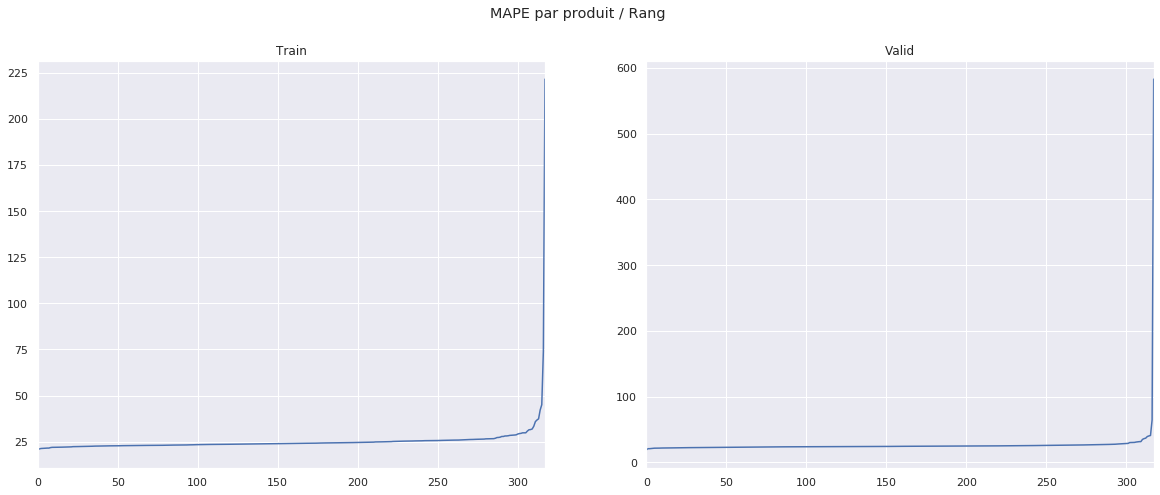
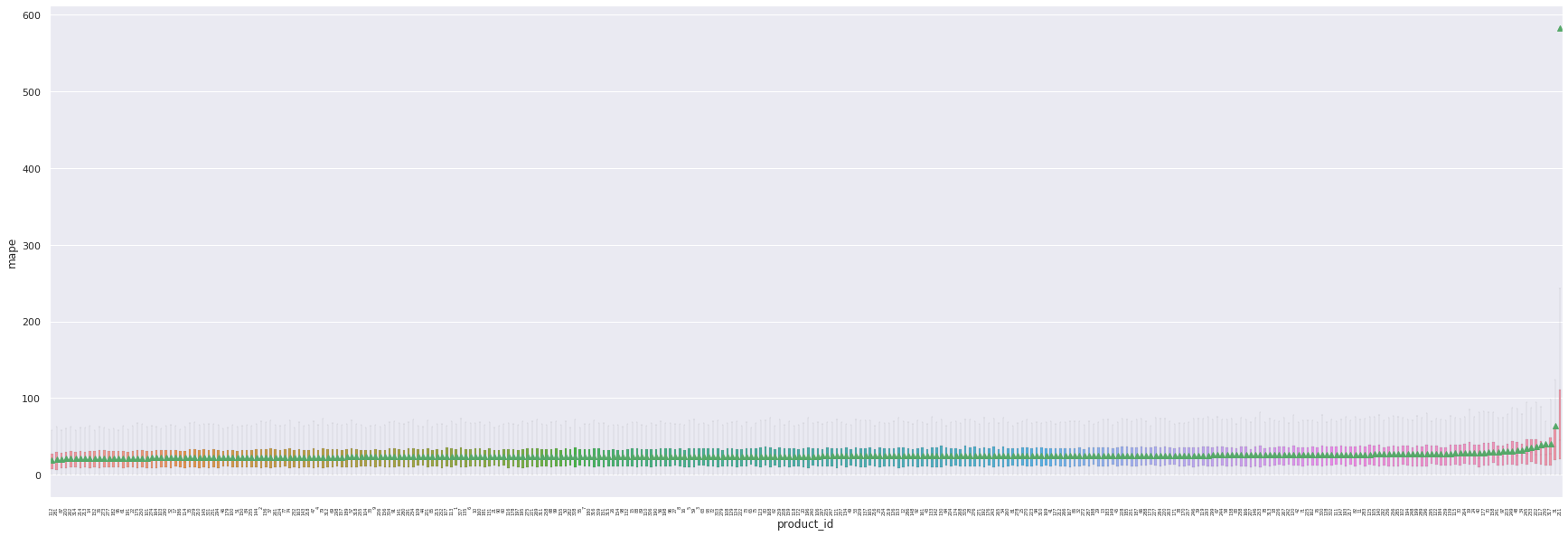
Comme constaté plus haut, le comportement de notre modèle est très variable en fonction de l’actif sur lequel il effectue les prédictions. Cela n’a rien d’étonnant car notre modèle ne prend pas en compte la structure particulière de chaque actif. Nous remarquons sur le boxplot suivant qu’un actif en particulier, le 211, provoque régulièrement une erreur extrême de prédiction (au sens de la MAPE). Après étude, il s’avère que le nombre d’erreurs extrêmes de prédiction est corrélé au pourcentage de features de volatilité manquante. Les features de l’actif 211, pour exemple, sont manquantes à plus de 50%.
Ici nous affichons les prédictions qui ont une MAPE supérieure à 2000:
predict |
TARGET |
mape |
product |
|
|---|---|---|---|---|
311899 |
0.114717 |
0.001008 |
11277.816056 |
211 |
365476 |
0.109641 |
0.000858 |
12685.100980 |
211 |
431366 |
0.087165 |
0.002504 |
3381.204884 |
230 |
444967 |
0.114946 |
0.000132 |
86715.917120 |
211 |
516022 |
0.099153 |
0.000578 |
17050.214170 |
211 |
626331 |
0.083922 |
0.000360 |
23198.076735 |
211 |
Ci-dessous, les 5 produits ayant la MAPE la plus élevée:
product |
mape |
|
|---|---|---|
0 |
211 |
582.764380 |
1 |
31 |
64.469789 |
2 |
317 |
40.887884 |
3 |
230 |
40.219172 |
4 |
117 |
39.270925 |
En soumettant à CFM nos prédictions effectuées sur le jeu de test, nous obtenons une MAPE de :
25.2709
Gradient Boosting basique¶
Dans la même idée que le modèle précèdent, nous entrainons un modèle Gradient Boosting (avec perte MAPE) sur toutes les données, avec les mêmes features que précèdemment. Après recherche des paramètres optimaux, notamment de taille et de profondeur des arbres, nous obtenons étonnament des résultats considérablement meilleurs.
MAPE |
|
|---|---|
train |
22.842474 |
validation |
23.265244 |
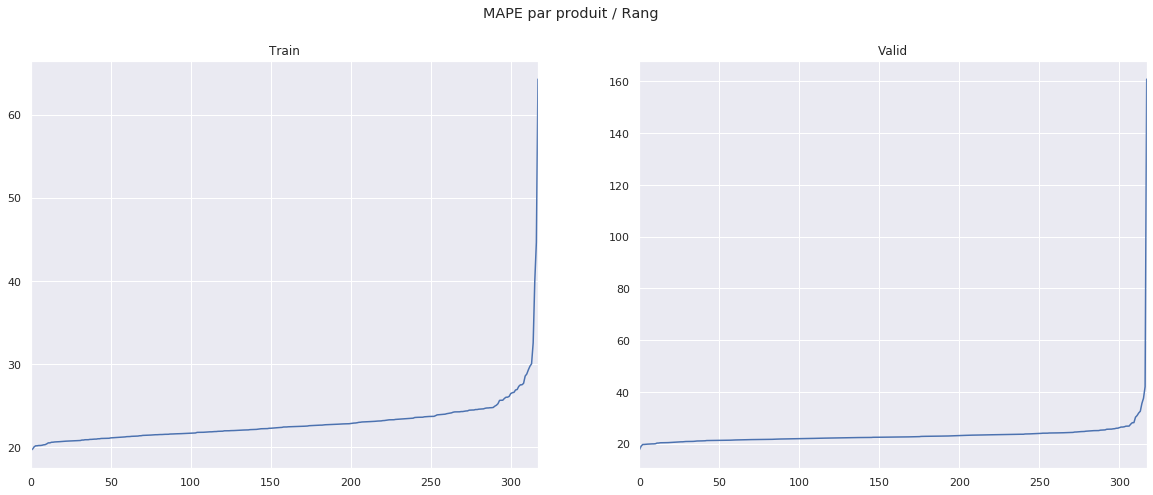
Le même problème de non-prise en compte de la structure de chaque actif apparaît à nouveau. Concernant les erreurs extrêmes, elles sont légèrement mieux gérées que précedemment. Encore une fois, l’actif 211 fournit la plus grande variance dans l’erreur de prédiction.
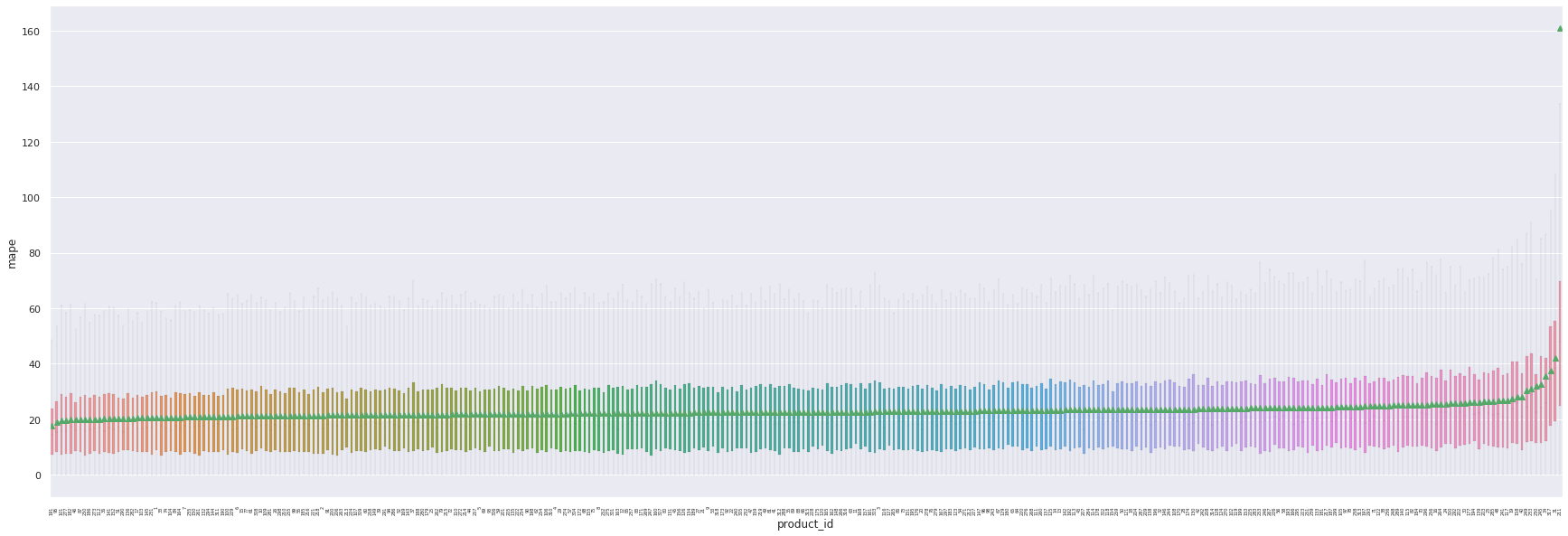
A nouveau, voici les prédictions ayant donnée une erreur de plus de 2000 de MAPE.
predict |
TARGET |
mape |
product |
|
|---|---|---|---|---|
311899 |
0.114717 |
0.001008 |
11277.816056 |
211 |
365476 |
0.109641 |
0.000858 |
12685.100980 |
211 |
431366 |
0.087165 |
0.002504 |
3381.204884 |
230 |
444967 |
0.114946 |
0.000132 |
86715.917120 |
211 |
516022 |
0.099153 |
0.000578 |
17050.214170 |
211 |
626331 |
0.083922 |
0.000360 |
23198.076735 |
211 |
Ci dessous, les produits les plus mal produit suivant la MAPE. Comme précédemment on remarque que les erreurs les plus extrêmes sont produites sur les mêmes actifs:
product |
mape |
|
|---|---|---|
0 |
211 |
160.895421 |
1 |
31 |
42.038608 |
2 |
317 |
37.570652 |
3 |
34 |
35.551697 |
4 |
245 |
32.545428 |
En soumettant nos résultats à CFM, nous obtenons comme nous pouvions l’espérer à la vue des erreurs d’entraînement et de validation, un résultat bien meilleur.
23.263
Modèles avancés¶
Dans toute la suite, nous considérons 80% de nos données d’entrainement comme ensemble de train, et 20% de nos données d’entrainement comme ensemble de validation. Ce partionnement est fixe pour tous les modèles, de par l’utilisation de la même seed pour réaliser le partionnement.
La partie précédente nous amène à deux constats majeurs :
Le nombre de features trop élevé provoque une instabilité dans nos prédictions.
Il est probablement essentiel de tenir en compte de la structure de chaque actif et de la corrélation entre les actifs afin d’améliorer nos prédictions.
Dans cette optique, nous proposons trois modèles plus avancés, qui tous impliquent la création d’un modèle par actif, soit 318 sous modèles :
Gradient Boosting actif par actif.¶
Nous entrainons 318 modèles GBM avec perte MAPE et recherche des paramètres optimaux, en considérant désormais pour chaque modèle les features suivantes :
Les volatilité aggrégées toutes les 30 minutes pour l’actif considéré.
La moyenne des volatilités de tous les actifs à la date donnée.
La principale raison pour laquelle nous avons aggrégé les features pour nous assurer que l’impact du bruit des features soit contenu.
Ce modèle nous donne une MAPE d’entraînement bien plus faible que le modèle baseline, mais étrangement une MAPE de validation très différente malgré recherche des paramètres optimaux, comme nous pouvons le constater :
MAPE |
|
|---|---|
train |
16.212051 |
validation |
24.443161 |
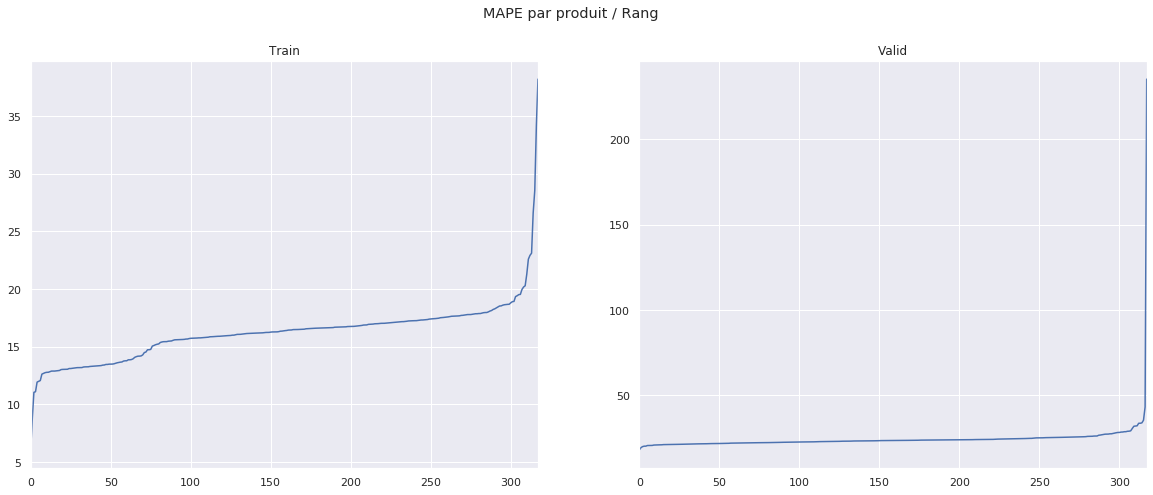
A nouveau, nous obtenons des erreurs extrêmes sur certains produits, en lien avec la proportion de features manquantes.
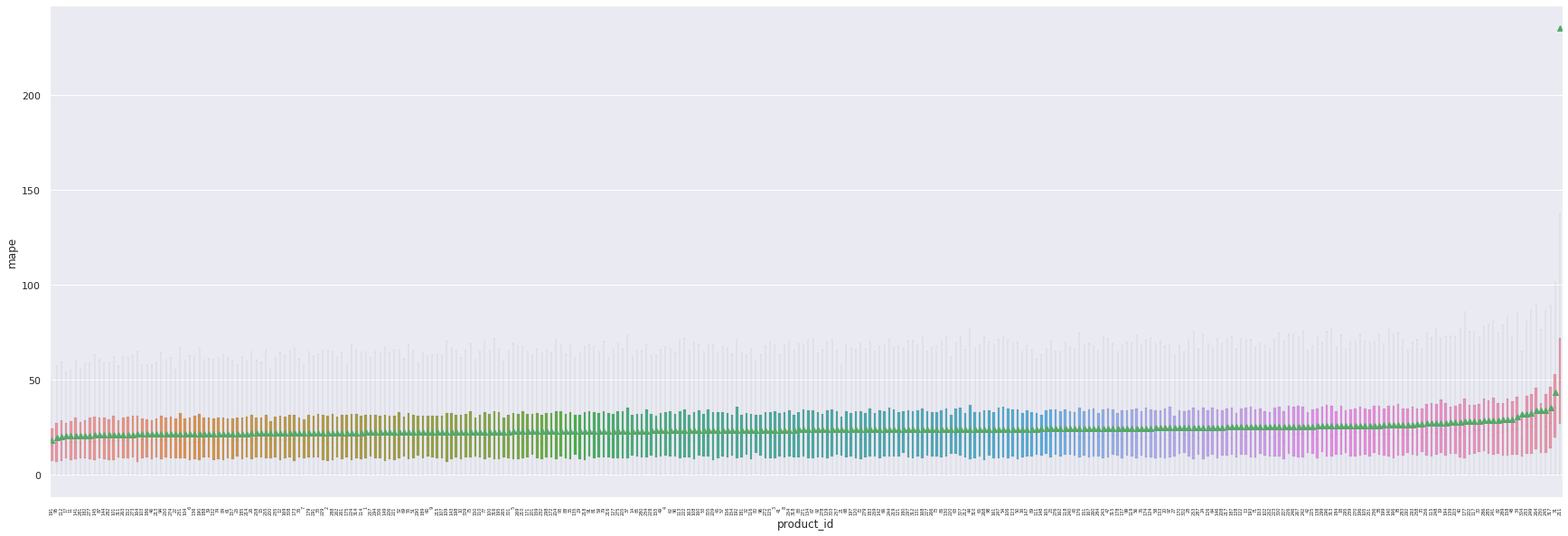
product |
mape |
|
|---|---|---|
0 |
211 |
235.049374 |
1 |
31 |
43.271284 |
2 |
317 |
35.506672 |
3 |
245 |
33.969012 |
4 |
230 |
33.734906 |
En soumettant nos prédictions à CFM, nous obtenons une MAPE de :
23.9384
Wide Adaptative Elastic-Net¶
L’idée de ce modèle est de pallier à l’absence de prise en compte de la corrélation entre actifs par le modèle linéaire baseline. Nous entrainons, pour chaque actif product_id, un modèle distinct.
En premier lieu, nous effectuons pour chaque actif product_id une liste contenant les actifs qui sont absent, dans le jeu d’entrainement, pour au moins une date durant laquelle product_id est présent. En considérant tous les actifs sauf ceux listés, nous obtenons ainsi pour chaque product_id, un “bloc” d’actifs constant à chaque date.
Une fois ce bloc obtenu, nous considérons les features suivantes :
Moyenne des retours pour chaque actif du bloc.
Volatilité aggrégée toutes les 30 minutes pour chaque actif du bloc.
La recherche des paramètres optimaux pour chacun de ses 318 modèles nous donne que la pénalisation Ridge est privilégiée. Cette recherche s’effectue ainsi :
Pour une liste de \(p\) entre \(0\) et \(1\) (p représentant la pondération entre les pénalisations \(l^1\) et \(l^2\)), rechercher le \(h\) (coefficient de pénalisation optimal) qui minimise la MAPE sur le jeu de validation. Cette recheche se fait en remontant le chemin de régularisation qu’utilise H2O pour trouver \(h\).
Pour chaque \(p\), comparer les modèles obtenus par la procèdure précèdente.
La prédiction actif par actif en utilisant cette procèdure nous donne les MAPE suivantes.
MAPE |
|
|---|---|
train |
19.285098 |
validation |
23.174364 |
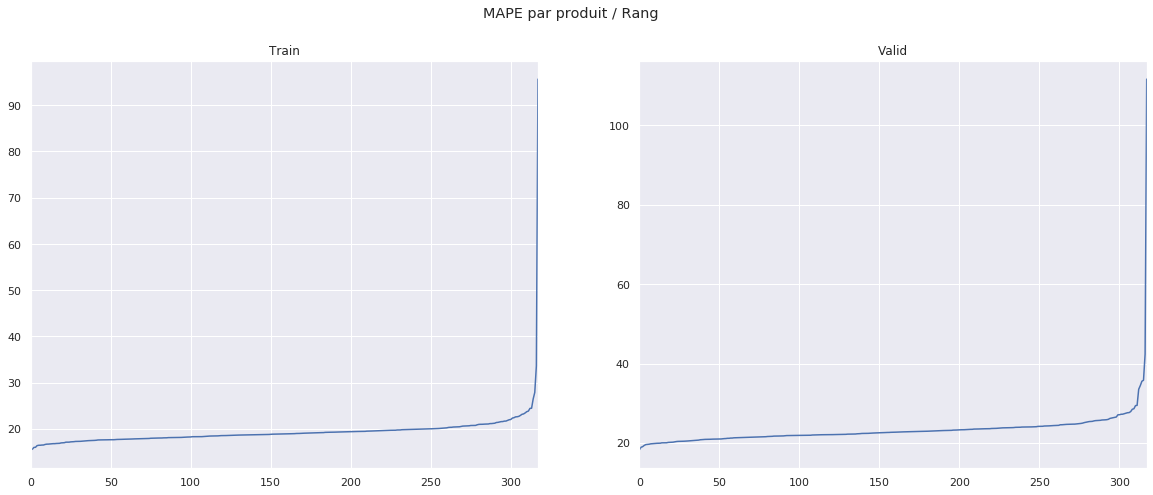
Nous pouvons constater que les produits atypiques sont bien mieux gérés avec ce modèle. Cela s’explique par le fait que l’utilisation de la corrélation entre les actifs permet de diminuer l’impact des valeurs manquantes pour les produits dont les features sont regulièrement imputées.
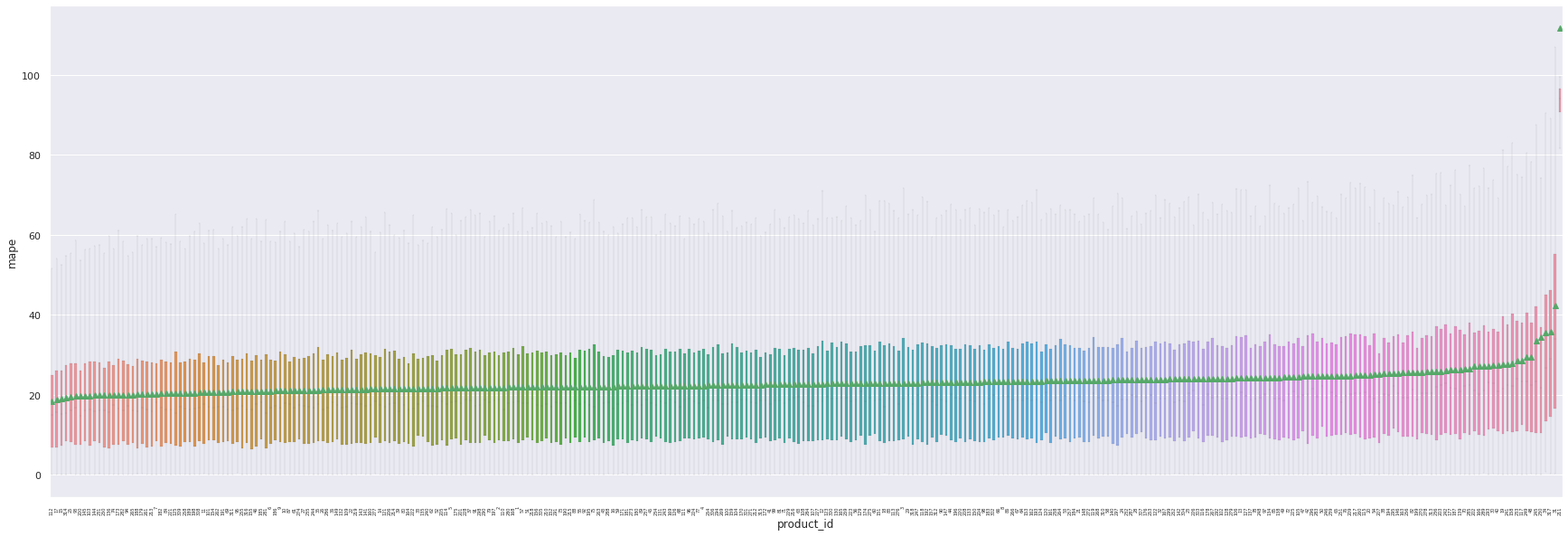
Si d’autant les actifs problématiques restent les mêmes, nous remarquons que leur MAPE reste contenue comparée aux modèles précedents.
product |
mape |
|
|---|---|---|
0 |
211 |
111.673404 |
1 |
31 |
42.371464 |
2 |
317 |
35.789674 |
3 |
34 |
35.535126 |
4 |
230 |
34.435568 |
La soumission de nos résultats à CFM donne le résultat suivant :
23.1077
Quantile Regression¶
Conditionnellement au product_id, nous avons effectué une regression
quantile, avec une perte MAPE, de la volatilité cible par rapport aux
features suivantes :
Volatilités de product_id aggrégées toutes les 30 minutes.
Moyenne de la volatilité de tous les actifs pour une date donnée.
La principale raison pour laquelle nous avons aggrégé les features pour nous assurer que l’impact du bruit des features soit contenu. L’absence de pénalisation dans l’implémentation de la Régression Quantile rend, d’après nos expérimentations, cette aggrégation essentielle à la qualité de prédiction du modèle.
On dispose des scores suivants sur l’ensemble de train et de validation (80%-20%) :
MAPE |
|
|---|---|
train |
21.738562 |
validation |
22.292690 |
Comme on peut le constater sur les graphiques suivants, on remarque que le score obtenu par notre méthode est à nouveau très variable en fonction de l’actif considéré.
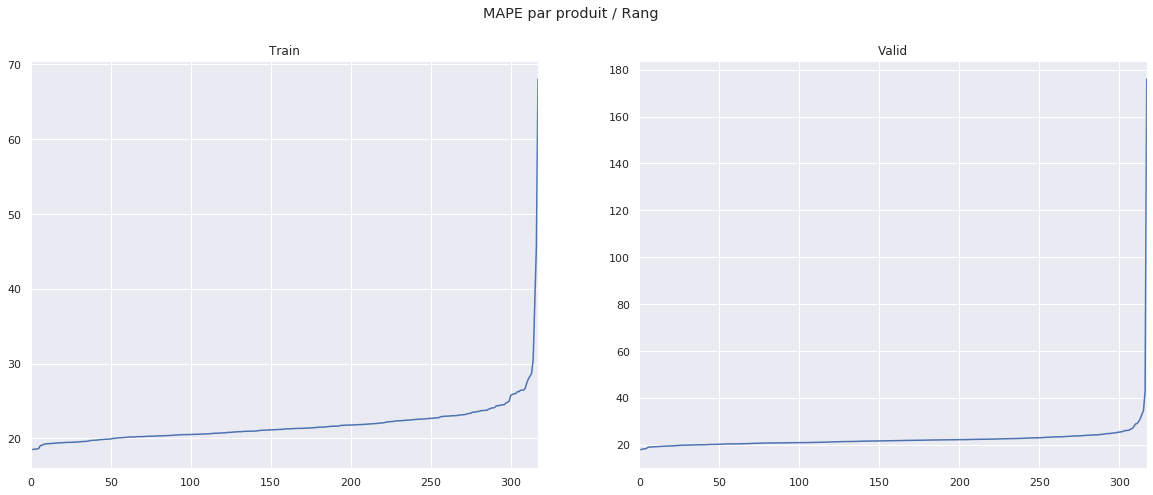
Cette variabilité des résultats peut, comme en témoigne le boxplot suivant, être en partie expliquée par la variabilité du nombre d’erreurs extrêmes de prédiction en fonction de l’actif considéré.
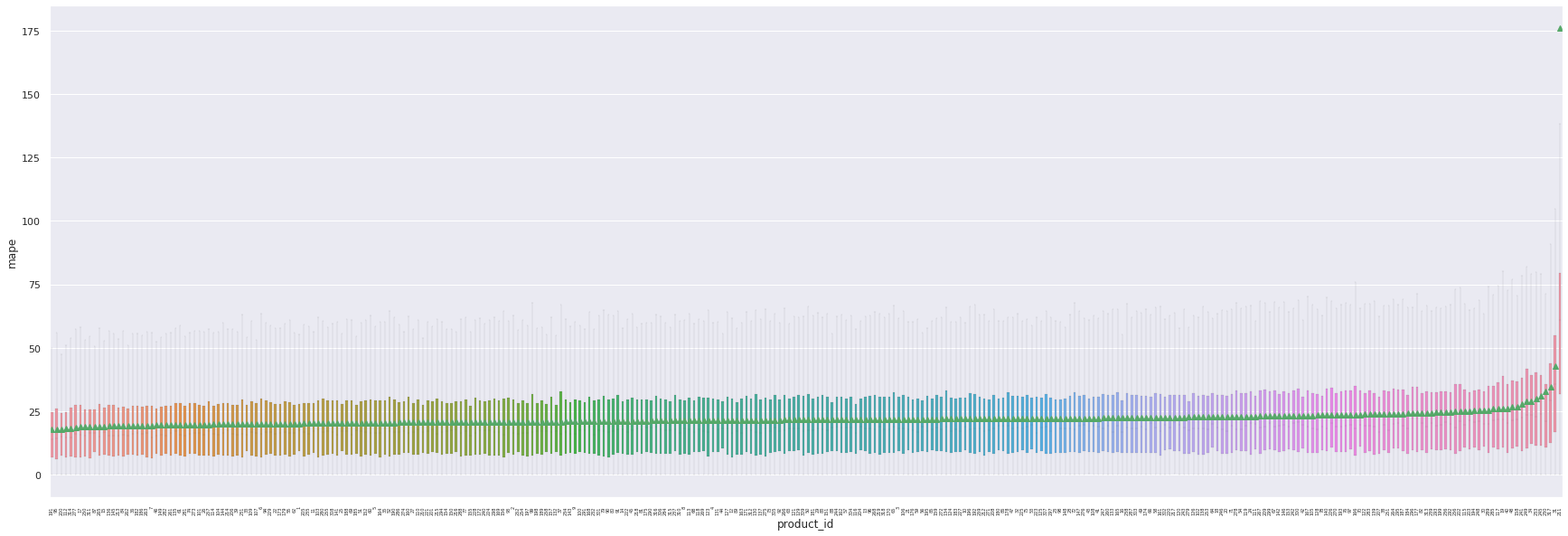
A nouveau, les 5 produits les moins bien prédits donnent des scores faussant considérablement notre MAPE totale.
product |
mape |
|
|---|---|---|
0 |
211 |
175.990856 |
1 |
31 |
42.835842 |
2 |
317 |
34.600058 |
3 |
230 |
32.935099 |
4 |
245 |
31.085524 |
En soumettant nos prédictions du jeu de test à CFM, nous obtenons la MAPE suivante, qui est de loin la meilleure obtenue jusqu’à présent :
Aggregation¶
Nous décidons d’essayer d’aggréger nos trois modèles avancés en effectuant une regression quantile sur leurs prédictions.
Pour cela, nous entrainons notre régression sur toutes les prédictions effectuées sur le jeu de validation, et nous appliquons ce modèle aux prédictions obtenues sur le jeu de test. Cela nous donne, après soumission des résultats à CFM, la MAPE suivante sur le jeu de test:
21.3592
Conclusion/Score par modèle¶
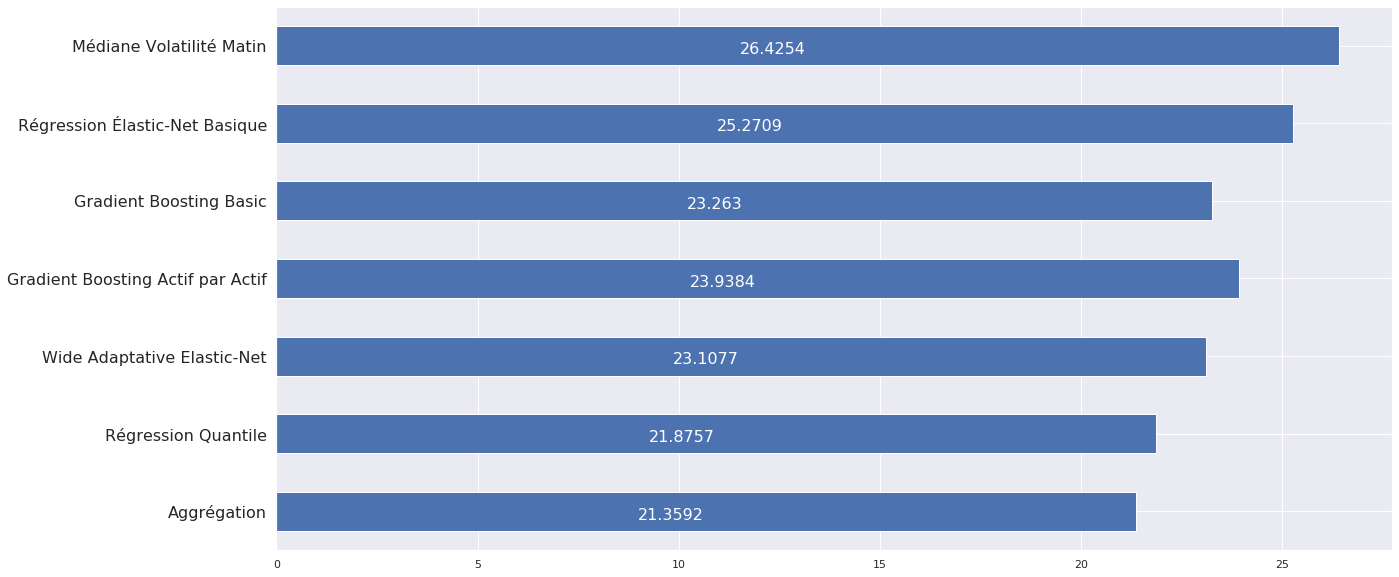
Voici, en comparaison, les scores obtenus par les meilleurs modèles du challenge, où les meilleurs scores sont obtenus par utilisation de réseaux de neuronnes :
20.7319
20.8711
20.908
20.9396
20.9749
21.1613
21.1846
21.1923 [CFM Model]
21.2706
21.2895
21.2921
Notre modèle final : 21.3592
Notre meilleur modèle obtient ainsi un score légèrement supérieur aux meilleurs modèles de cette compétition. Comme évoqué en introduction, cela nous confirme qu’il est très difficile de faire mieux que des modèles linéaires.
Certaines améliorations pourraient potentiellement être obtenues en améliorant les transformations effectuées sur les données, et en utilisant une méthode plus fine d’imputation des valeurs manquantes. De plus, la méthode wide adaptative utilisée ici semble prometteuse, et mériterait d’être testée suite à un entrainement sur un plus grand jeu de données. Dans la même idée, notre méthode d’aggrégation pourrait elle aussi être considérablement améliorée en effectuant une aggrégation différente pour chacun des actifs, si nous avions accès à plus de données d’entrainement.
Cependant, le principale problème se situe au niveau de la qualité des données : les données financières sont par natures très aléatoires bruitées. De plus, l’anonymisation des actifs et la randomisation des dates ne permet pas l’utilisation de toutes les informations qu’il serait possible d’utiliser dans un cadre purement industriel. Ainsi, par exemple, la connaissance du jour de la semaine permettrait d’utiliser le fait que les gestionnaires d’actifs liquident leur position à la veille du week-end. La connaissance du mois et de l’année permettrait d’adapter le modèle au fait que les périodes d’élections engendrent des instabilités sur les marchés. La connaissance précise des actifs aurait aussi une utilité, permettant de les regrouper par secteurs d’activités et lieu d’échange et ainsi d’utiliser certaines structures de corrélation plus fines entre les produits.